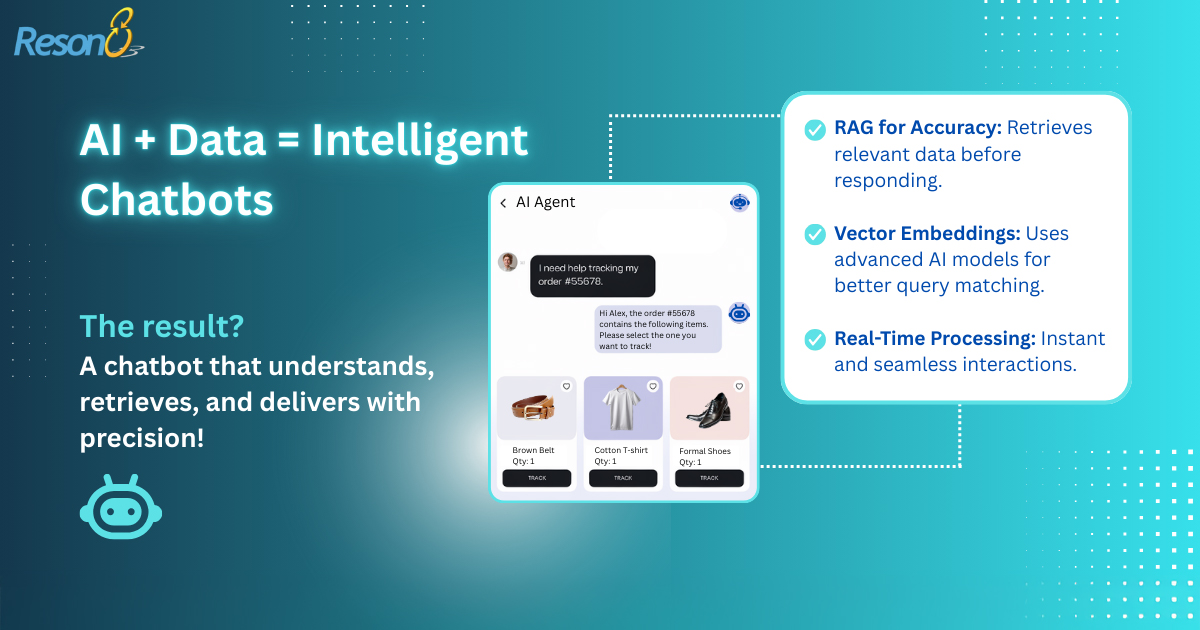
Inside the Architecture of a Smart Chatbot: Powered by RAG, LLMs, and Reson8
As businesses seek smarter, faster, and more context-aware AI solutions, Retrieval-Augmented Generation (RAG) is emerging as a game-changer in chatbot design.
In this post, we’ll explore the key components behind a high-performing RAG-based chatbot architecture. We’ll break down how technologies like Hugging Face embeddings, Chroma vector stores, FastAPI, and the Llama 3 model from Groq Cloud come together to deliver precise, dynamic responses. And more importantly, we’ll show you how Reson8 makes deploying this intelligence seamless for your enterprise needs.
What Is a Chatbot ?
A chatbot is an AI-driven assistant that simulates human conversation through text or voice. It interprets user queries, delivers relevant information, and even performs tasks like scheduling or data retrieval—often at scale.
Modern chatbots use Natural Language Processing (NLP) and machine learning to continuously improve accuracy and interaction quality.
Where Do Chatbots Make the Most Impact?
Chatbots aren’t just a customer support shortcut, they’re transforming operations across industries:
- Customer Service: 24/7 intelligent support that accelerates response times and delegates complex cases to workforce.
- E-commerce: Guide customers through product discovery, FAQs, or even abandoned cart recovery.
- Healthcare: Book appointments, offer symptom checks, or provide first-line triage.
- Lead Generation: Qualify prospects, deliver personalized recommendations, and hand off warm leads to your CRM.
- Recruitment: Schedule interviews, answer FAQs, and streamline the application process.
- Internal Support: Help employees with IT, HR, or policy-related questions—without opening a ticket.
LLMs + RAG = Next-Level Chatbot Intelligence
To understand why this chatbot model excels, we need to explore two foundational technologies:
Large Language Models (LLMs)?
LLMs are AI models trained on massive volumes of text to understand and generate language. Think of GPT (Generative Pre-trained Transformer) by OpenAI, Llama by Meta, or BERT (Bidirectional Encoder Representations from Transformers) by Google).
LLMs are characterised by their massive size, often involving billions or even trillions of parameters, which allow them to handle complex tasks such as text generation, question answering, summarisation, and translation. The key advantage of LLMs lies in their ability to understand the intricacies of language, including context, tone, and meaning, making them extremely powerful for various NLP applications.
Retrieval-Augmented Generation (RAG)
RAG enhances LLMs by connecting them with up-to-date, external knowledge sources. This two-step process ensures the output isn’t just well-written it’s accurate and relevant.
How RAG Works:
- Retrieve: Pulls relevant info from vector databases or documents (like PDFs, manuals, or reports).
- Generate: Feeds that info into the LLM to craft a response that is both contextual and factual.
Together, LLMs and RAG enable a chatbot that’s intelligent, informed, and business-ready.
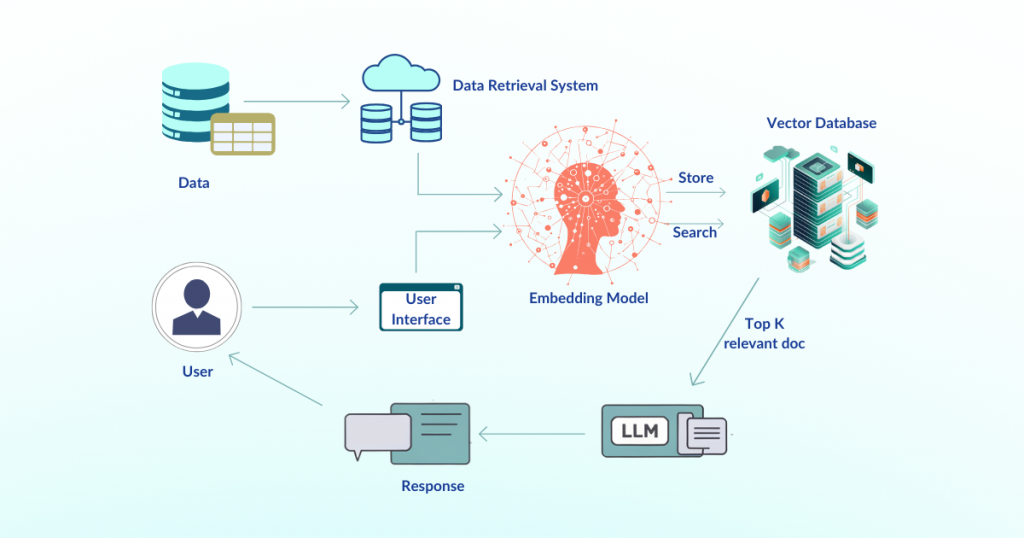
Let’s Break Down the Chatbot Architecture
Building a chatbot like this involves multiple components—each playing a critical role in how your AI understands and responds.
1. Data Embedding
To enable fast and relevant retrieval, all your documents (think policies, catalogs, help articles) are embedded into vectors.
- Hugging Face’s all-MiniLM-L6-v2 model is used to convert text into semantic vector format.
- These vectors are stored in Chroma, a specialized vector database that allows the bot to search and match documents in real time.
With Reson8, you can feed the chatbot PDFs, guides, or knowledge bases—it turns them into structured, searchable intelligence automatically.
2. Real-Time Interactions with FastAPI
FastAPI powers the chatbot’s backend. It’s responsible for:
- Handling user queries
- Initiating the retrieval process
- Orchestrating the full response generation pipeline
It acts as the system’s command center—managing requests efficiently and scaling for multiple users at once.
3. LLM-Powered Generation with LLaMA 3 (Groq Cloud)
Once the relevant data is retrieved from Chroma, it’s passed to LLaMA 3, hosted via Groq Cloud.
This is where the magic happens. The model interprets the context, understands user intent, and generates a response that’s fluent and fact-based.
4. The RAG Workflow
Here’s how the full process flows:
- Query Embedding: User’s message → vector form (using Hugging Face).
- Document Retrieval: Vector compared to stored content in Chroma → relevant chunks returned.
- Response Generation: Chunks fed into LLaMA 3 → personalized, context-rich response returned.
All this happens in milliseconds, offering a seamless, human-like experience.
From Data to Dialogue Simplified with Reson8
The chatbot’s combination of data embedding, real-time conversation management, and Retrieval-Augmented Generation allows it to deliver accurate, context-aware responses. With technologies like Fast API, Hugging Face embeddings, and the Llama 3 model, the system efficiently manages user interactions, document retrieval, and response generation, ensuring a smooth and engaging conversational experience.
Reson8 brings this architecture to life customized for your business, secure for your data, and integrated with your workflows.Ready to build a smarter chatbot? Book a demo with Reson8 now






